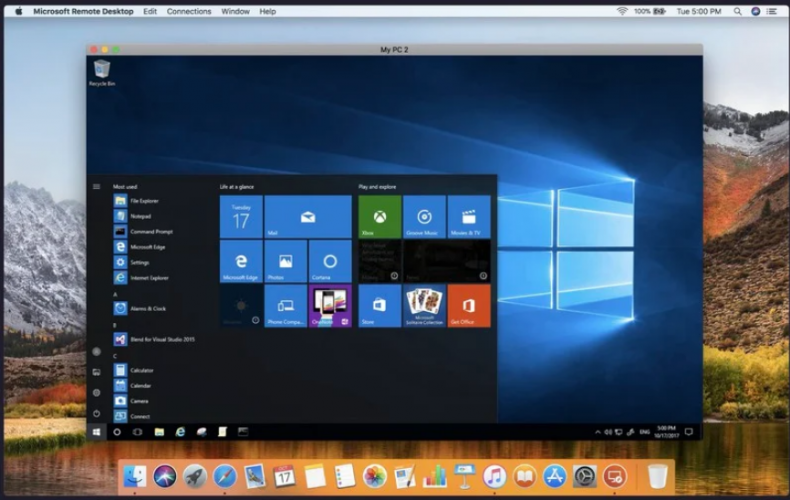
微软的远程桌面一直是办公不可缺少的必需品,是在装PD这样的虚拟机太麻烦也很重。 可惜微软的远程桌面锁定在美国区,无法直接使用,找的分离版不久就会有cpu占用高等的问题出现,而每次找分离版很痛苦,幸运的是老外做了一个分享所有mac最新微软软件的站点,链接也都是微软官方的,这里真的要吐槽,既然都有下载地址了为啥不公开呢。 微软软件for mac地址:https://macadmins.software/ 里面Office等全家桶都有,如果你是下载Microsoft Remote Desktop远程桌面那么直接用地址,会…

挂载文件是/etc/fstab 如果是3.73前的版本直接修改即可,如果是之后的版本请修改/etc/openmediavault/config.xml中下面xml节点的信息: 注意只要修改“dir”就可以修改挂载的路径,其他不需要动。如果是5以后的版本使用以下两个命令中的一个来重新生成fstab,这是omv的命令行工具,可以防止fstab的误操作导致系统无法启动,第二个命令是最新omv的。 omv-mkconf fstab omv-salt deploy run fstab Post Views: 2,483

最近在用时间机器备份我的macbook,总是觉得很慢,于是察看了下局域网之间的连接质量。 前面一篇说到Cat5E的网线被老鼠咬断了一半后被网卡自动纠错还保持百兆感到震惊,新买的2021mbp m1 pro连接速度居然只有30MB+,可是路由器是荣耀3Wifi6,这速度太慢了。 我用来测试速度的工具还是iperf3,之前已经测试过nas有线到pc的速度已经千兆,现在就差笔记本了。按住alt健后点击wifi图标可以查看当前wifi的详细信息,这里要喷一下苹果这部分的UI做的真的不好,不可靠,跟内置的设置不同步,还有内置…

Algorithm 'AesGcm' is not supported on this platform. 如果使用了aes-gcm的dotnet程序会在macos上报错 AesGCM是一个非常流行的对称加密算法,所以对这个报错还是很惊讶的,一开始以为是dotnet core 适配apple sillicon的问题,查阅文档后发现原来macos都有这个适配错误。Mac的安全策略不允许第三方程序调用系统的加密接口,所以只能使用第三方的加密库。这里真的要喷一下微软,既然不可以用那就给出解决方案么,让我复制黏贴一下不好么…

解决“No usable version of libssl was found“ 最近调试一个项目,其他都好好地,就是这个项目出现各种诡异的问题,也没有stack_trace,卡了好久,今天发现最后一行小字No usable version of libssl was found ,终于按图索骥解决了。 这是一个.net 5.0的项目,开始我挺担心它在ARM下不兼容的问题,但是可以顺利在Rider中成功build并运行,不得不说苹果的兼容生态和Rider的适配做的太好了,也正是因为这种错觉才让我大意了吧,所以如果…
一般设置都是放在appsettings.json,为了安全,特地把一些敏感信息如密码移到环境变量中去,那么如何设置带有子元素的变量呢比如ConnectStrings: Windows下用冒号“:”分级比如: ASPNETCORE_ConnectionStrings:BlogDb=conn_str Linux/Mac下用双下划线“__”分级比如: ASPNETCORE_ConnectionStrings__BlogDb=conn_str Post Views: 1,931
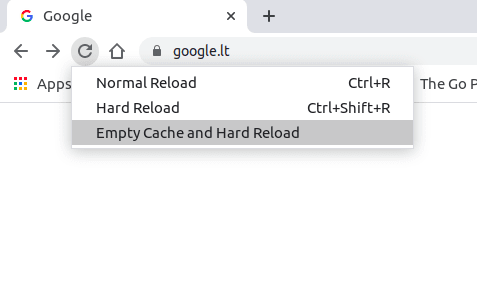
如果没有必要请不要使用301,当你不确定的时候先用302。因为这个转发缓存是存在客户端的,一旦设置301后服务端无法通知客户端更新,除非客户自己清除缓存。 Chrome中301作为永久转发会一直保持下去,上图中就是当打开开发者工作台时可以右击刷新按钮清除缓存。 有一个特殊情况上面的方法不奏效,那就是如果是A.com转发到B.com,如果是这样就要开启工作台中的preserve log后再清除。 Post Views: 1,719

开发怎么可能离得开数据库呢~ 这里的EFC和以前的EF不是一个东西,就跟.net core和以前的.net不一样是一个道理。 Core这个家族可以说是完全跟开源接轨了,不管是运行方式,交互方式如果熟悉开源组件的同学就会感觉跟自己家一样,当然还没那么接地气,下面就是在用EFC CLI Tool时碰到的几个坑。 如果你的项目不是一个程序集,那么你不得不指定开始项目和目标项目就比如得这样:“dotnet ef list -p 目标项目目录 -s 开始项目目录”,这里我就很不理解,也困惑了我好一会,如果知道开始项目,那么作…

如果你有不得不用sqlserver的理由,并且手上只有MAC时那么这篇文章可能对你有帮助。 第一个要解决的就是数据库的GUI管理软件,SQL Server Management Studio (SSMS)肯定是没办法在Mac上跑了,这里最佳的替代就是Azure Data Studio,看名字就知道它的作用就是管理Azure上的数据,所以不管是sql server也好还是postgresql也好都可以用它管理。装好之后会发现它绝对是在vs code同一个team弄出来的,连很多默认样式都一样,所以跟vs code一样…
最近在配置.net的remote开发环境,用了整套VS Code Remote的三大件,在用container时总是提示: 一头雾水,docker版本20了都,可能的理解就是它没找到docker。可是信息有限,好在开源项目有issue,作者介绍了debug的办法,适用于进一步调试。 Developer Tools就是chrome的开发栏,是同一个东西,能够看到UI的日志,已经发现就是Docker version这个命令的返回值出错,作者在issue中反复提到会不会是没加入Path,我不信。最后他终于提到了,如果再v…

最近评论
jinzhao 发布于 4 年前(05月31日)
jinzhao 发布于 4 年前(05月31日)
匿名 发布于 4 年前(05月08日)
匿名 发布于 4 年前(04月18日)
jinzhao 发布于 6 年前(06月04日)